调整训练数据出场顺序大模型就能变聪明! 无需扩大模型/数据规模
- 2025-09-06 17:25:22
- 446
模型训练重点在于数据的数量与质量?其实还有一个关键因素——
数据的出场顺序。
对此,微软亚洲研究院提出了一种全新的文本数据组织范式DELT(DataEfficacyinLMTraining),通过引入数据排序策略,充分挖掘训练数据潜力,在不同模型尺寸与规模下都达到了良好性能。
△数据效率与效能提升
该方法用优化训练数据的组织方式来让语言模型学得更好,还不用增加数据量或扩大模型规模。
来看看是怎么做到的。
首先,我们先来理清几个概念。
在语言模型训练中,数据使用效率至关重要。现有研究多关注于数据效率(DataEfficiency),即如何通过数据选择提升模型训练效率并保持优异性能。
然而,数据效能(DataEfficacy),即如何通过数据组织增强模型训练表现,却常常被忽视。
以烹饪为例,数据效率就像在市场挑选新鲜、合适的食材,而数据效能则像名厨把握投放调料的时机与分寸,让菜品发挥出最佳风味。
为了避免过拟合,当前的大语言模型往往在海量数据上进行训练,并且训练的次数非常有限,甚至仅进行一次完整的训练周期(epoch=1),这与早期模型依赖多次迭代训练(epoch>>1)截然不同。
这些变化让数据呈现的先后顺序对结果影响巨大。
早期的AI模型类似于让学生多次反复翻阅同一本书,在多轮学习中慢慢补齐细节;而现在更像只给一遍通读,不再反复回看。
这就对阅读顺序提出了极高要求,必须精心规划学习材料出现的先后和结构。因此,训练样本的组织顺序显得尤为关键。然而,关于这一点的研究却很少。
基于此观察,微软亚洲研究院最新提出的文本数据组织范式DELT,通过引入数据排序策略,充分挖掘训练数据潜力,实现了数据的高效利用与效能提升。
DELT范式不但通过数据选择提升效率,选取高质量数据,加快训练速度;
而且通过数据排序提升效能,在预训练和后训练阶段都显著提升了模型性能,且适用于通用、数学和代码等多领域任务。
研究首先定义了数据训练效能(DataEfficacy),是指通过优化训练数据的组织方式来最大化语言模型的性能表现,而无需改变数据内容或模型架构。
与以往关注的“数据训练效率”(DataEfficiency)侧重数据筛选的研究目的不同,数据效能强调对训练数据的评分和排序,以充分挖掘数据的潜在价值。
数据顺序在语言模型训练中的潜力尚未被充分挖掘,数据效能旨在通过合理的数据组织方式,使模型在有限的训练数据和资源下实现更高的性能和泛化能力,成为提升语言模型性能的一种新兴方法。
△DELT范式架构
DELT(DataEfficacyinLMTraining)是一种创新的文本数据组织范式。
它集成了数据评分(DataScoring)、数据选择(DataSelection)和数据排序(DataOrdering)三大核心组件。
数据评分根据特定的属性为每个样本赋予分数,如:难度、质量、多样性等。
数据选择通过评分筛选出最优子集(如:top-k、按阈值筛选等),然后数据排序根据评分重新组织所选择数据的呈现顺序(如:基于课程学习的分数从低到高排列)。为了兼顾数据处理效率,DELT范式的数据选择和数据排序共用数据评分的结果。
因此,数据评分的规则设置非常重要。于是,研究还提出了Learning-QualityScore(LQS)方法。
△LQS打分方式
该数据评分方式结合了质量和可学习性两个关键指标,不但可以筛选出低质量数据,而且也能捕捉数据在不同阶段的训练价值,进一步提供了可靠的数据排列顺序。
为了进一步提升数据效能,团队还提出了一种全新的折叠排序方法FoldingOrdering(FO)。
基于课程学习的排序(即,按分数升序排序)可能导致模型遗忘和数据内部分布偏差。
折叠排序策略通过多层“折叠”,将数据按分数分层并多次采样,无重复且均衡分布。
△Folding排序方式
相比随机打乱或单一排序,它既保留难度排序优势,又避免模型过度遗忘或依赖特定数据,提升了鲁棒性和泛化能力。
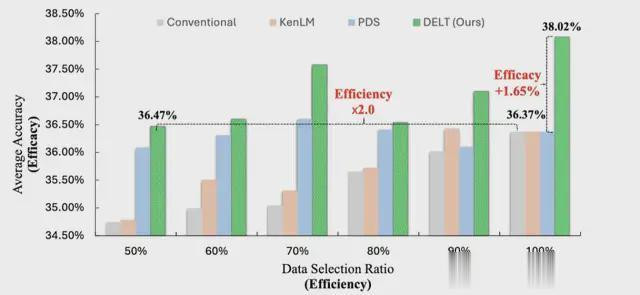
与传统随机排序方法相比,DELT范式不仅通过减小数据规模提升了训练效率;而且在不同模型尺寸和数据规模下,在各种评测集上都显著提升了模型性能。
△不同数据规模和模型尺寸下的结果
DELT给Data-centricAI领域带来了全新思路。
看来,类比于人类教学实践,讲究个性化与按部就班地安排学习内容,AI训练也需要类似的学习方法。
论文链接:https://arxiv.org/abs/2506.21545
代码链接:https://github.com/microsoft/DELT
- 上一篇:钟南山不到岁时房子被日本飞机炸塌
- 下一篇:阅兵网友神评论
